When I first started in the IT industry I remember one of my first projects. The purpose was just to move data from one system to another and I remember wondering if that is all there was to it. I discussed this with my mentor who told me that this is what all IT is about: “Moving data from one place to another.” I received this insight with great puzzlement and apprehension. Surely IT is about creating new opportunities, better ways of doing things, entertainment, smartness and improving processes.
But now, decades later I have come to a deeper appreciation of this insight: everything in IT really is basically about moving data from one place to another. What data to move, and why, is a problem for business development and research and development. Even showing or capturing data in a UI is moving data from a device to a server. Data is the foundation for everything.
To make anything work properly it is necessary to understand and manage how to move this data from one place to another. It’s that simple. If you are not in complete control of what that data is and how it is moved you are not going to succeed. Without this, no amount of innovation or business development will matter. This is why we need to build the data foundation on which digitalization, automation, artificial intelligence and the efficiency and quality gains they bring are built.
Sketching the data foundation
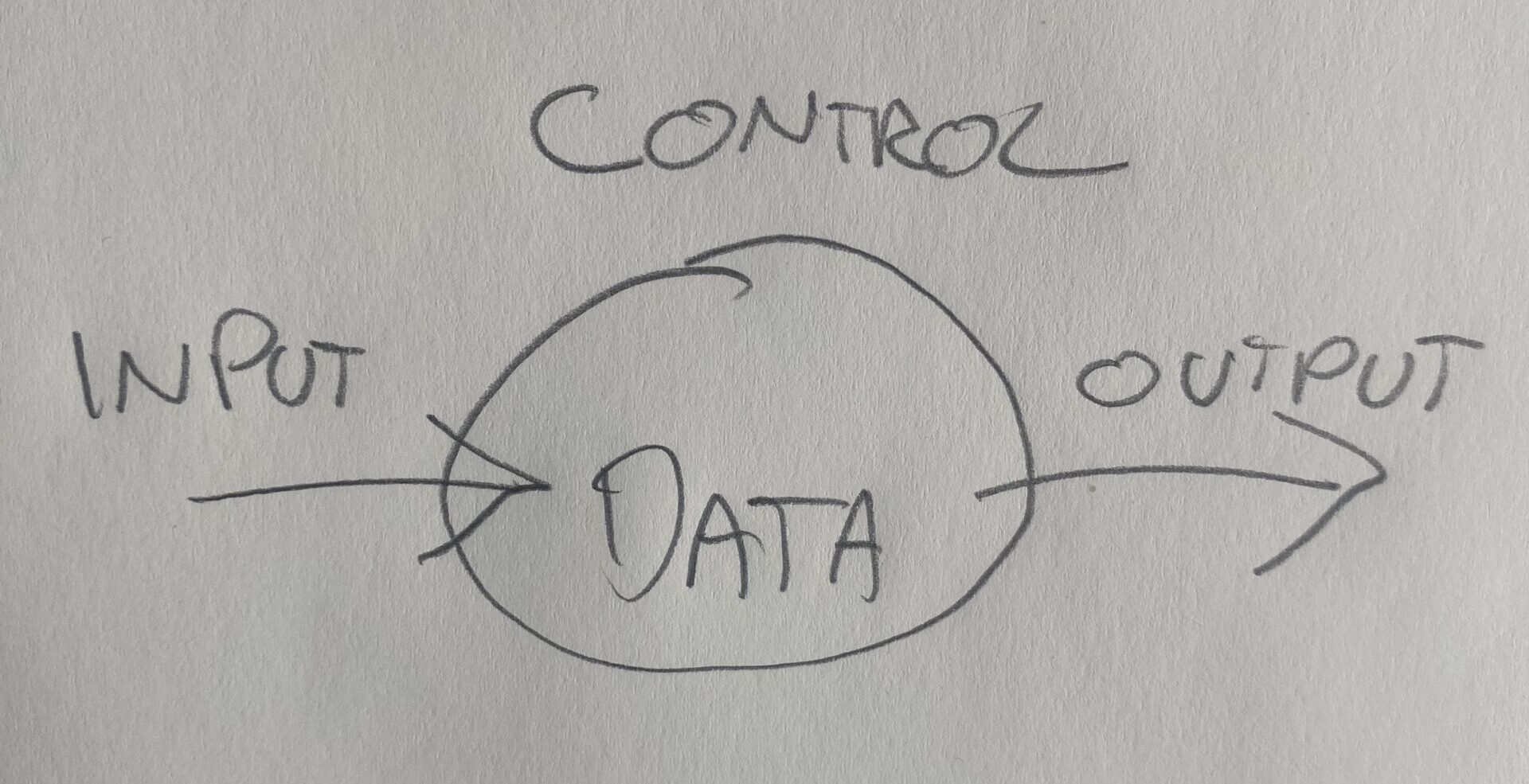
We can expand on this. A good way to understand what a data foundation is, one should focus on data input, control and output. If these three parts work together you have built a solid data foundation on which anything can be built. Without alignment on these three parts the result will be unpredictable.
The first part is the input. This is where data capture appears. We can capture data in two ways. It is either done through a UI where users input or manipulate data such as an HR system or through devices that measure or monitor data. An example could be a medical device or health tracker.
The second part has to do with control and concerns how we structure, manage and govern the data. Data governance defines ownership and processes for changing data structures. Data management concerns ensuring data quality and value as well as modelling the data structures. Risk management makes sure that data risks are identified and handled and that access to data is aligned with regulation and business objectives.
The final part, the output, is where data is moved and used. First we need to make sure the data is stored in the optimal way. To move the data we need to manage interoperability and build the right ways to exchange data whether through synchronization, ETL, APIs or events. The data must also be appropriate for analytics to create real insights and finally AI, where data is crucial for adequate functioning of the solution.
It is just moving data from one place to another, but this deceptively simple observation contains significant complexities that require us to understand what data is captured, how it should be structured, how it creates value and how it should be consumed.
The data foundation consists in how you manage input, control and output of data. If you do it well the foundation will be solid and you will be able to build skyscrapers and majestic domes, if you don’t do it well you will struggle to erect simple apartment blocks and most likely be surrounded by suburban sprawl.
If you are able to manage the interplay between data input, control and output you have a world class data foundation. If you do not, your organisation will have increased risks, errors, inefficient operations and not be able to harness the transformative potential of AI.