Tag: data
-
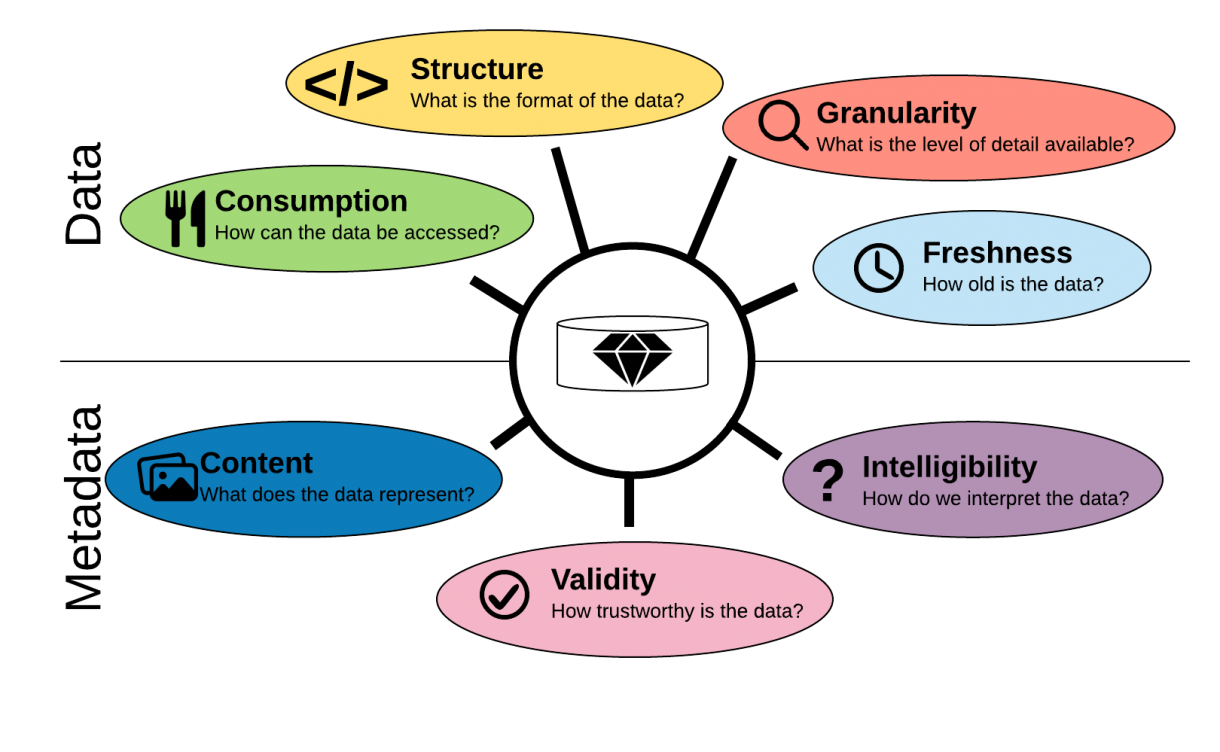
The 7 Dimensions of Data Value and How To Improve It
One thing that you quickly realise when you are trying to build a solid data offering is that data is not just data. Just like food is not just food and clothes not just clothes. A Metallica T-shirt is fine if you are going to sit on your couch and watch football with your bro, but…
-
Data Is the New Oil – Building the Data Refinery
“Data Is the New Oil!” Mathematician and IT Architect Clive Humby seems to have been the first to coin the phrase in 2006 where he helped Tesco develop from a fledgling UK retail chain to an inter continental industry titan only rivaled be the likes of Walmart and Carrefour through the use of data through…
-
The Data Deluge, Birds and the Beginning of Memory
One of my heroes is the avant garde artist Laurie Anderson. She is probably best known for the unlikely hit “Oh Superman” in the eighties and being married to Lou Reed, but I think she is an artist of comparable or even greater magnitude. On one of her later albums is a typical Laurie Anderson song…